Comment visualiser des données avec DataWarrior ? [Tuto]
Il y a peu de temps nous avons vu comment bien débuter avec DataWarrior, un outil gratuit de data visualisation.
N’hésitez pas à voir (ou revoir) les sections installation et importation des données qui sont nécessaires pour commencer cet exercice.
À la fin de ce tutoriel, vous saurez réaliser plusieurs types de graphiques avec DataWarrior et serez en prime imbattable sur les mariages en France en 2017 😉
Table des matières
Importation des données
Pour ce tutoriel, nous allons utiliser des données de l’Insee mises à disposition sur le site https://www.data.gouv.fr. Nous travaillerons sur les mariages en 2017.
- Connectez-vous sur https://www.insee.fr/fr/statistiques/3718132?sommaire=3596198
- Téléchargez le fichier « etatcivil2017_mar2017_csv.zip » (icône à gauche) et le fichier pdf contenant les explications sur les variables en cliquant sur : « Accéder à la liste des variables du fichier Mariages »

- Dézippez le fichier « etatcivil2017_mar2017_csv.zip » pour récupérer le fichier « etatcivil2017_mar2017.csv »
- Datawarrrior a besoin d’une « , » ou d’une tabulation pour repérer les colonnes du fichier. Ouvrez le fichier « etatcivil2017_mar2017.csv » dans un éditeur de texte (personnellement j’utilise Smultron sous Mac). Dans ce fichier les colonnes sont séparées par des « ; », substituez-les par des « , » à l’aide de « Rechercher » et « Remplacer ». Enregistrez le nouveau fichier sous « mon_fichier_etatcivil.csv ».
Je vous propose une autre méthode sous Linux ou Mac à utiliser dans le Terminal :
cd myaccount/Bureau/dossiermariage
// on entre dans le dossier qui contient le fichier etatcivil2017_mar2017.csv
more etatcivil2017_mar2017.csv
//on regarde le fichier et on constate qu'il y a des ";" entre les colonnes
sed 's/;/,/g' etatcivil2017_mar2017.csv > mon_fichier_etatcivil.csv
// on substitue tous les ";" par des ",”
// on génére un fichier modifié mon_fichier_etatcivil.csv- Nous pouvons maintenant ouvrir notre fichier dans DataWarrior en cliquant sur « File »> »Open » ou en glissant-déposant le fichier sur le raccourci du logiciel.
Graphique en barres
Définition
Un graphique en barres dit encore diagramme à barres ou bar plot en anglais peut représenter les différentes modalités ou catégories d’une variable avec des barres rectangulaires tracées verticalement ou horizontalement. Par exemple la variable Année peut comporter 12 catégories : les mois. Les hauteurs ou les longueurs des barres sont proportionnelles aux valeurs qu’elles représentent.
Cas pratique : répartition des mariages selon les mois en 2017
Vous l’avez compris nous allons nous intéresser à la variable mariage. Essayons de voir si, en 2017, il y a eu des mois privilégiés pour les mariages. Pour repérer la variable, nous allons ouvrir le fichier Contenu_etatcivil2017_mar2017.pdf que nous avons téléchargé précédemment. La colonne sur laquelle nous allons travailler s’intitule MMAR et correspond au mois de mariage. Les mois sont codifiés par des chiffres allant de 1 pour janvier à 12 pour décembre.

- Dans DataWarrior, après avoir ouvert le fichier, on voit que le fichier comporte 231339 lignes en scrollant jusqu’à la dernière ligne de la table.

- Cliquez maintenant sur l’intitulé de la colonne MMAR, les mois se classent par ordre croissant. En cliquant une nouvelle fois, vous verrez leur classement par ordre décroissant.
- Dans le bloc à droite, il est possible de filtrer les variables en jouant avec le curseur ou en cliquant sur les cases à cocher. Par exemple il est possible d’isoler les femmes et les hommes (F et M) en filtrant la variable SEXE1.
- Nous allons maintenant agrandir la fenêtre 2D View située en bas de l’écran à gauche, car nous souhaitons visualiser en 2D la répartition des mariages selon les mois de l’année. Tirez vers le haut puis vers la droite la fenêtre en utilisant les zones contenant des point ou cliquez sur le petit bouton « Maximize view » situé à coté de « xyz » dans la barre horizontale en haut du graphe.
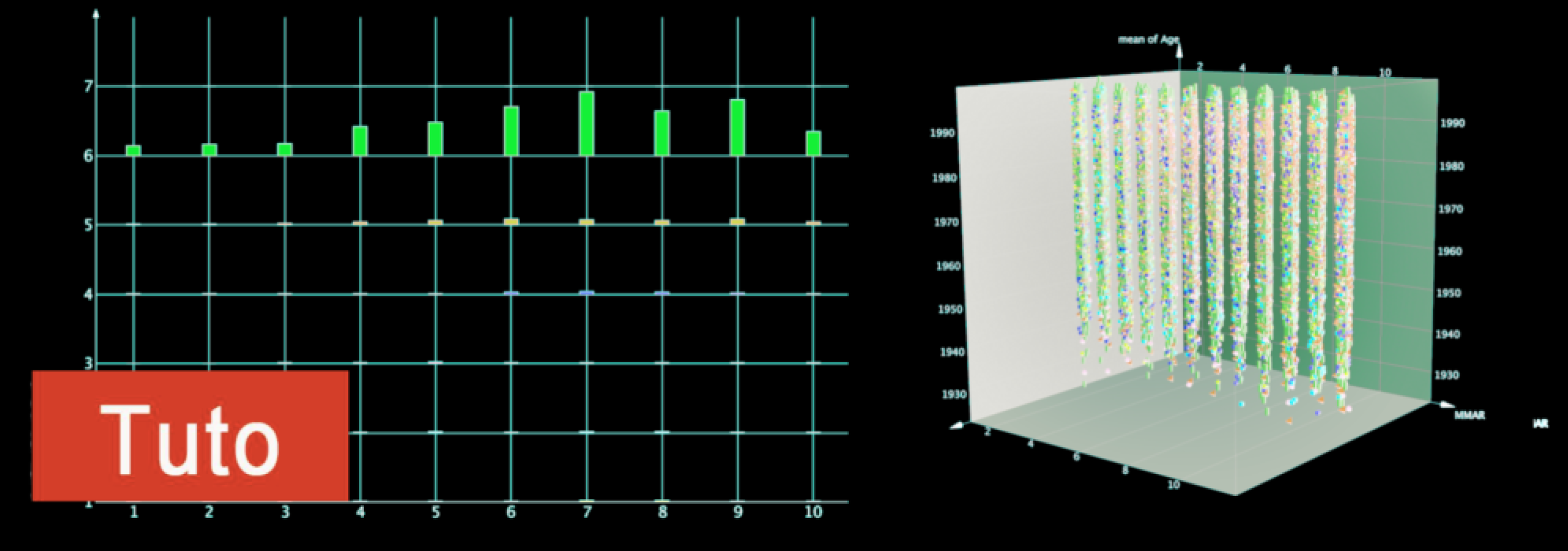
- Dans la section 2D View, avec un clic droit nous allons choisir “Set Preferred Chart Type” et l’option « Bar Chart ». Ensuite dans « xyz », nous sélectionnons la variable « MMAR » pour x et « <unassigned> » pour y.

- Avec un clic droit sur la figure, en sélectionnant « Set Statistical View Options », affichez le nombre de mariages (cochez « Show value count N » dans l’onglet « Box Plot/Bar Chart »).

- Je vous propose enfin de mettre un peu de couleur en sélectionnant « Set Marker Color » avec un clic droit sur le graphe. Choisissez la variable « MMAR » et laissez le gradient de couleur. Résultat : nous observons que le mois où il y a eu le plus de mariages en 2017 est juillet. Pour aller plus loin et conclure, il faudrait calculer si la différence du nombre de mariages entre les mois est réellement significative… mais pour cette fois, nous en resterons là.

Nuage de points
Définition
Un nuage de points ou diagramme de dispersion ou encore scatter plot en anglais est une représentation graphique qui permet de visualiser la relation entre 2 (graphe 2D) ou 3 variables (graphe 3D). La position de chaque point dépend des valeurs des variables x et y (ou x y z pour un graphe 3D) qui lui correspondent.
Cas pratique : relation entre l’âge moyen des couples, le jour, et le mois du mariage en 2017 et en 3D
Nous allons maintenant tenter de voir s’il y a une relation entre trois variables : l’âge moyen des couples, le jour et le mois du mariage. Pour cela, il faudra réaliser un graphe 3D avec une variable par axe. Agrandissons la fenêtre 3D View pour travailler plus confortablement et regardons à nouveau le fichier Contenu_etatcivil2017_mar2017.pdf afin de repérer les variables qui nous intéressent ici : JSEMAINE, le jour de la semaine du mariage, MMAR que nous connaissons déjà et les variables ANAIS1, l’année de naissance du conjoint 1 et ANAIS2, l’année de naissance du conjoint 2.

L’année de naissance indiquée est celle du conjoint, nous souhaitons l’âge moyen du couple ; il faut donc créer une nouvelle variable représentant la moyenne des variables ANAIS1 et ANAIS2 dans une nouvelle colonne.
- Dans DataWarrior, sous le menu « Data », cliquez sur « Merge Column ». Dans la fenêtre qui s’ouvre, sélectionnez « ANAIS1 » et « ANAIS2 » en maintenant la touche Shift enfoncée. Par défaut, DataWarrior crée une nouvelle colonne intulée « Merged Data », je vous suggère de la renommer « Age » (champ « New Column Name »), décochez également la case « Remove source columns after merging » pour sauvegarder les colonnes d’origine.
- Dans la nouvelle colonne « Age » les années de naissance des deux conjoints sont séparées par des « ; ». Cela va nous permettre d’utiliser une fonctionnalité intéressante de DataWarrior qui peut générer automatiquement la moyenne des deux valeurs de la colonne (ou encore choisir de garder le plus grande ou la plus petite des valeurs…). Après un clic droit sur le nom de la colonne, sélectionnez « Show Multiple Values As » et choisissez « Mean » pour générer la valeur moyenne des dates de naissance des mariés.

- À ce stade, nous sommes prêts à réaliser un nuage de points en 3D. Dans la barre horizontale de la fenêtre 3D View, cliquez sur « xyz » et choisissez « MMAR » pour x , « Mean of Age » pour y et « <unassigned> » pour z. Vous pouvez diminuer le volume des sphères qui représentent les couples avec « Set Marker Size » (clic droit sur la figure puis réglez la taille avec le curseur) et les colorer en fonction du jour de la semaine avec « Set Marker Color ». Certains points se confondent car il y a plusieurs mariages en même temps, pour les dissocier utilisez « Set Marker Jittering » (clic droit sur la figure puis cochez les cases « Jitter in X-direction » et « Z-direction » en laissant décoché l’axe des y et nous glissez le curseur légèrement vers la droite pour éloigner les points).

- Faites pivoter la figure avec Pomme + clic gauche (sur mac) pour observer par exemple que quand l’âge moyen du couple augmente, le jour du mariages n’est plus uniquement le samedi et le nombre de mariages a tendance à augmenter à partir du mois d’avril.
Boîtes à moustaches
Définition
Une boîte à moustaches ou box-plot en anglais permet de résumer graphiquement une variable en identifiant les valeurs extrêmes et en donnant une idée de la répartition des observations.
Cas pratique : comparaison de l’âge des hommes et des femmes marié(e)s en 2017
Nous allons maintenant comparer la répartition des mariés hommes et femmes selon leur âge. Dans le fichier Contenu_etatcivil2017_mar2017.pdf l’on repère les variables concernées ici : il s’agit des variables ANAIS1, l’année de naissance du conjoint 1 et ANAIS2, l’année de naissance du conjoint 2, manipulées précédemment et de SEXE1, le sexe du conjoint 1 (F et M) et SEXE2, le sexe du conjoint 2 (F et M).

- Il y a un mélange de femmes et d’hommes dans les colonnes SEXE1 et SEXE2, nous devons donc créer une table contenant une colonne qui fusionne les colonnes SEXE1 et SEXE2 et une colonne avec l’année de naissance. Plusieurs méthodes sont possibles, je vous propose d’utiliser quelques lignes de commandes Unix dans le Terminal.
cd myaccount/Bureau/dossiermariage
// on entre dans le dossier qui contient le fichier mon_fichier_etatcivil.csv
more mon_fichier_etatcivil.csv
// on regarde le fichier et on constate qu'il y a des "," entre les colonnes
awk -F, '{print $1 "," $3}' mon_fichier_etatcivil.csv > conjoint1.csv
awk -F, '{print $6 "," $8}' mon_fichier_etatcivil.csv > conjoint2.csv
// avec Awk l’option –F permet d'indiquer de type de séparateur.
// pour le conjoint 1, on sélectionne les colonnes 1 et 3, pour le conjoint 2, les colonnes 6 et 8- Nous avons maintenant deux fichiers : conjoint1.csv et conjoint2.csv
- Dans DataWarrior, ouvrez le fichier conjoint1.csv puis dans le menu « File » sélectionnez dans « Append File » le fichier conjoint2.csv pour ajouter les lignes du fichier conjoint2.csv au fichier ouvert. Une fenêtre s’ouvre et nous demande le nom du « Existing dataset name », inscrivez ici « conjoint1 », le nom du New dataset sera le nom du fichier, « conjoint2 ». Ensuite assignez ANAIS2 à la colonne ANAIS1 et SEXE2 à la colonne SEXE1 pour fusionner toutes les données dans 2 colonnes.

- Nous pouvons renommer les colonnes avec un clic droit « ANAIS1 » et en cliquant sur « Set Column Alias ». « Column Alias to be used for ANAIS1 » devient par exemple « Naissance » et « Column Alias to be used for SEXE1 » devient « Homme&Femme ».

- C’est parti pour le box plot ! Agrandissez la fenêtre 2D View et avec un clic droit sur le graphe choisissez “Set Preferred Chart Type” et l’option « Box plot ». Ensuite dans « xyz », sélectionnez la variable « Homme&Femme » pour x et « Naissance » pour y. Je vous conseille de réduire la taille des marqueurs comme d’habitude avec « Set Marker Size ». Vous pouvez ajouter des statistiques avec « Set Statistical View Options » : par exemple l’écart type (« standard deviation ») , la moyenne (« mean »), la médiane (« median ») et le nombre d’individus N.

- Vous constatez, qu’en 2017, les hommes étaient un peu plus vieux en moyenne que les femmes le jour du mariage. Encore fois pour valider cette hypothèse, il faudrait tester la significativité de cette différence.
Pour conclure
Dans nous n’avons appris à créer un bar chart, un scatter plot en 3D et un box plot à l’aide de DataWarrior et à manipuler des tables de données. Vous avez maintenant les bases pour continuer à explorer cet outil, c’est à vous de jouer !
